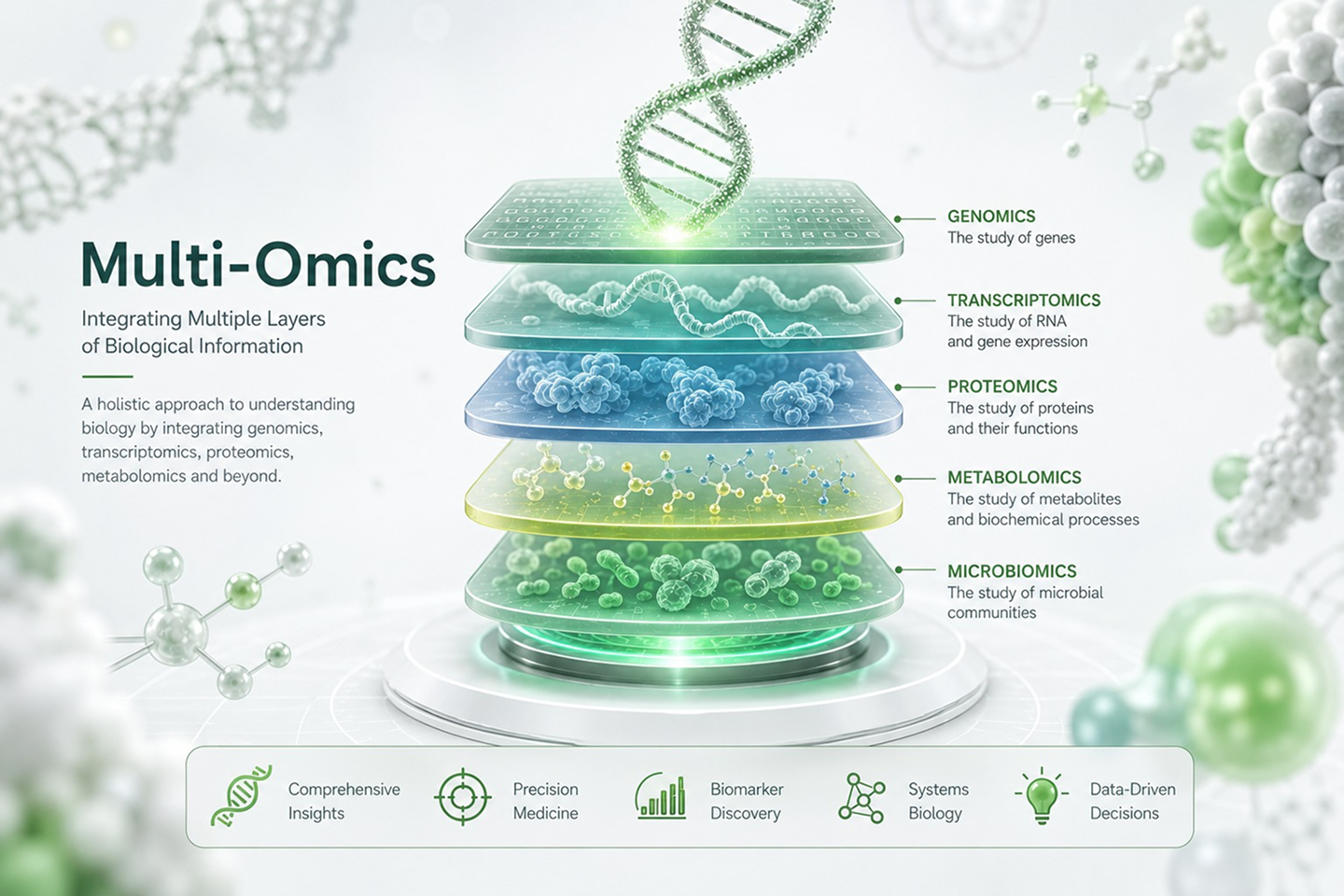
-
Sequencing
- Genomics Sequencing
- Transcriptomics
- Epigenomics
- PacBio SMRT Sequencing
- Nanopore Sequencing
- Microbiome
- Single-Cell Sequencing
- Genome Editing & Sequencing
-
Genotyping
- Whole Genome SNP Genotyping
- SNP Fine Mapping
- CNV Genotyping
- DNA Fragment Service
- APOE genotyping
- APOE genotyping
- Population Genetics
- Bioinformatics
-
Microarray
- Transcriptomics Microarray
- DNA Methylation Microarray Service
- Global Diversity Array Service
- Genomics Microarray Services
- Cloud
- Solutions
- Company