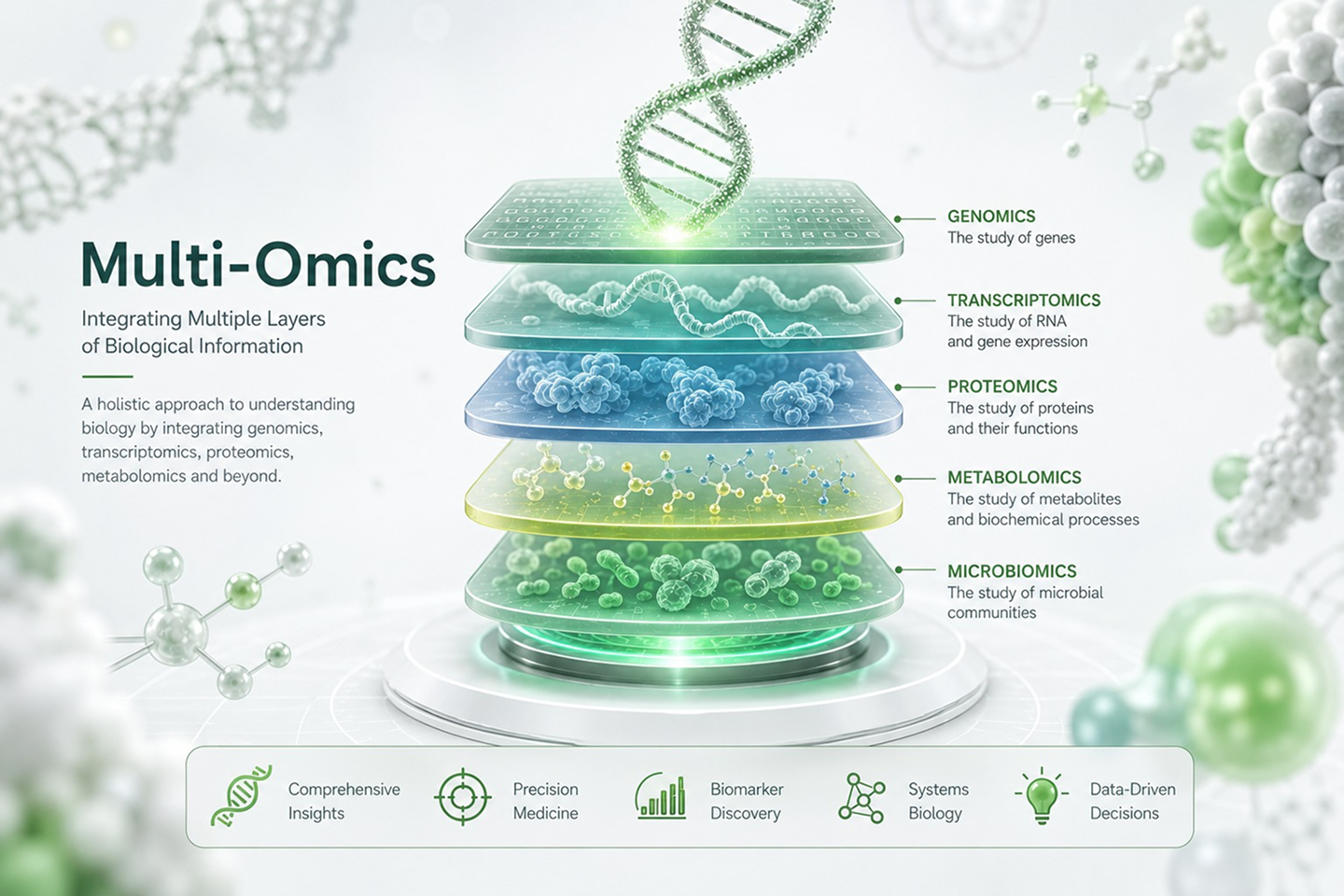
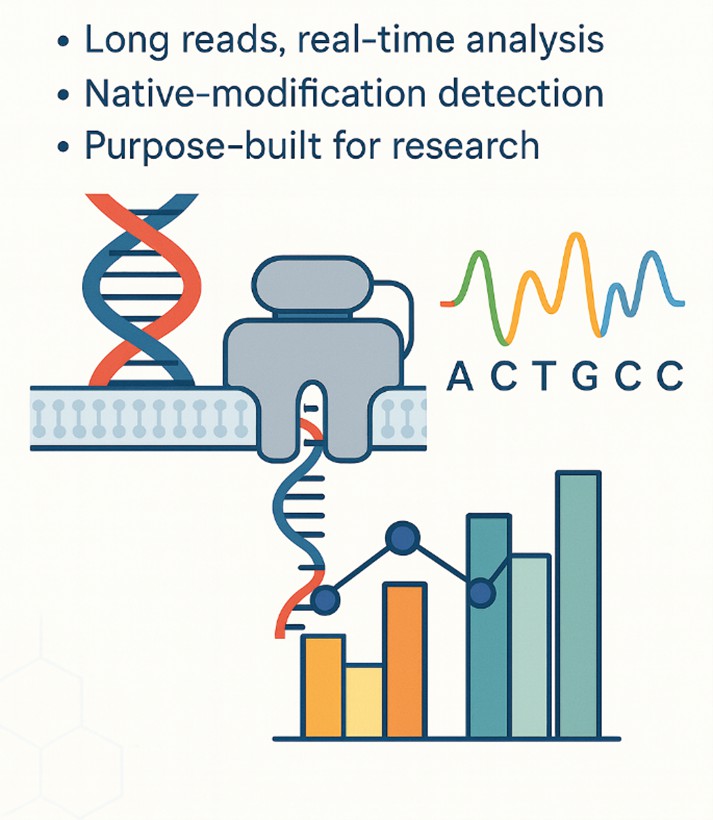
Nanopore sequencing passes a single DNA or RNA molecule through a protein nanopore embedded in an electrically resistant membrane. As each nucleotide transits the pore, it disrupts the ionic current in a sequence-specific manner. These current changes are recorded in real time and decoded into nucleotide sequences (A, T, C, G — or RNA bases) by a neural-network basecaller such as Dorado.
Unlike Illumina (sequencing-by-synthesis with cluster amplification) or PacBio (optical detection of fluorescently labeled nucleotides in zero-mode waveguides with circular consensus), Nanopore reads the native molecule directly. No amplification, no synthesis, and no optical measurement are involved. The raw signal carries not only base identity but also modification information (5mC, 6mA, and RNA modifications), which can be extracted bioinformatically without additional sample preparation.
Why it matters for your research:
- Ultra-long reads (exceeding 1 Mb routinely, with record reads surpassing 2 Mb). Span telomeres, centromeres, segmental duplications, and large structural variants that cannot be resolved with short or mid-length read platforms.
- Real-time data streaming. Sequencing results are generated as the molecule passes through the pore, enabling live yield monitoring, adaptive sampling (enrich or deplete target regions on-the-fly), and immediate run termination when sufficient data is collected.
- Direct RNA and native modification detection. Sequence RNA molecules without reverse transcription or amplification bias. Detect DNA methylation (5mC, 6mA) from genomic reads and RNA modifications (m6A, pseudouridine, inosine) from direct RNA reads — all from the raw signal, with no bisulfite conversion or enrichment steps required.