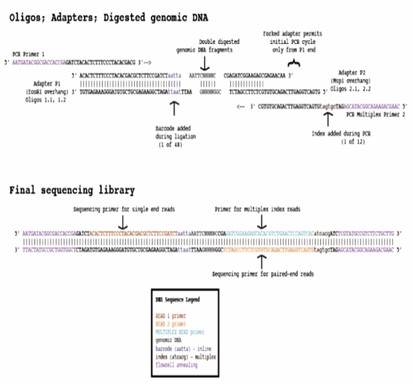
ddRAD-seq FAQs
1. How long does it take to get results from ddRAD-seq?
The typical turnaround time for ddRAD-seq results varies depending on project size and complexity but usually ranges from 4 to 8 weeks.
2. Can we customize the ddRAD-seq service for specific needs?
Yes, we offer tailored solutions to meet unique project requirements, including custom protocol adjustments and data analysis options.
3. What types of samples are suitable for ddRAD-seq?
ddRAD-seq can be applied to various sample types, including blood, tissue, and other genomic DNA sources from plants, animals, and microorganisms.
4. Can ddRAD-seq be used without a reference genome?
Yes, ddRAD-seq does not require a reference genome, making it suitable for species where reference genomes are not available.
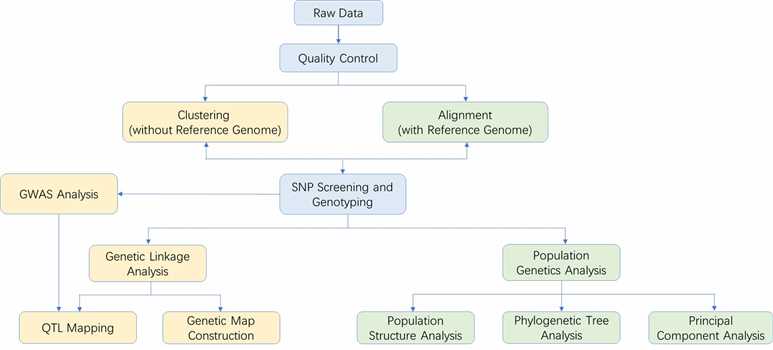
5. How to choose the appropriate reduced-representation genome technology?
When selecting the appropriate simplified genomics technology, consider the following four factors to design your research strategy:
Reference Genome
- With Reference Genome: Using a reference genome helps reduce errors due to homologous or repetitive sequences, facilitates LD analysis, selection analysis, and GWAS. This is suitable for conventional RAD sequencing and PE151 sequencing.
- Without Reference Genome: ddRAD-seq is recommended.
Sequencing Strategy
- Double Digest: For short fragments, paired-end (PE) sequencing may result in significant adapter overlap and is not ideal for long read lengths; single-end (SE) sequencing is recommended for short fragments.
- Long Fragments: Long reads can detect more variant information but require sufficient coverage.
- Short Reads: Improves sequencing depth per restriction site, enhancing SNP detection accuracy.
- Non-Reference Species: SE sequencing is recommended to avoid data wastage.
Number of Markers
- High Marker Density: Conventional RAD sequencing is suitable for analyses requiring high-density markers.
- Complex Genomes and Large Sample Sizes: GBS sequencing is ideal for complex genomes and large sample volumes.
PCR Amplification Artifacts
- PCR Bias: May lead to heterozygous sites being misidentified as homozygous or introduce errors. Conventional RAD sequencing can remove PCR duplicates using fragment sequence information, while GBS and ddRAD-seq cannot.