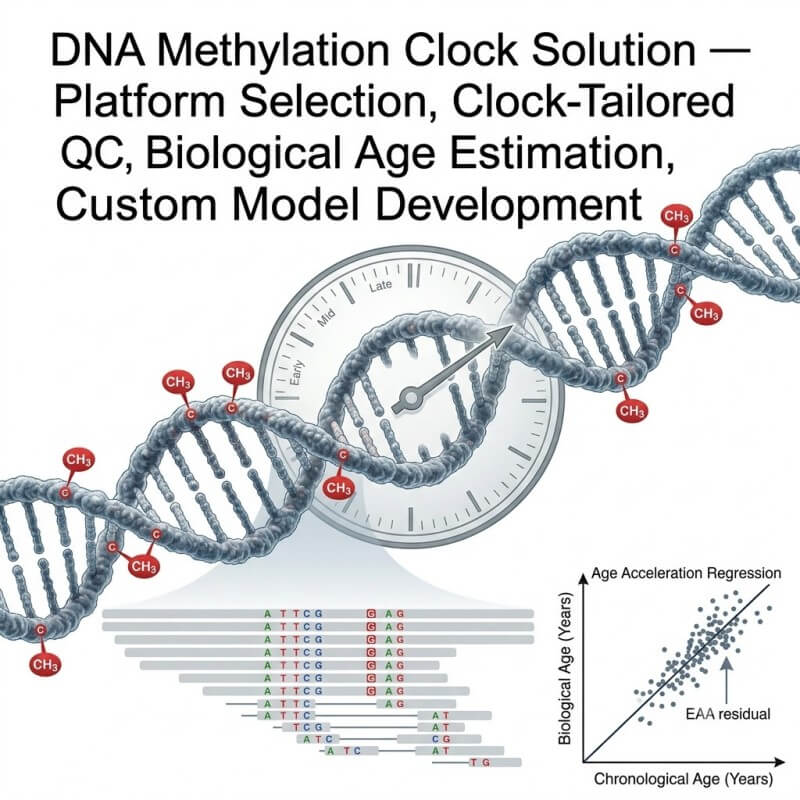
DNA Methylation Clock Sequencing Solution
Home
> DNA Methylation Clock Sequencing Solution
DNA Methylation Clock Sequencing Solution
Epigenetic aging clocks have transformed how researchers measure biological age, evaluate intervention effects, and identify age-associated methylation signatures. Whether your project targets a first-generation multi-tissue clock, a tissue-specific model, a pace-of-aging biomarker, or a custom clock trained on your own cohort, the reliability of the output depends on methylation data generated with clock-aware experimental design and analysis parameters.
CD Genomics provides a complete DNA methylation clock solution — from platform selection consulting through sample QC, library preparation, sequencing or array processing, methylation calling, CpG coverage filtering, normalization, and biological age estimation. We work with high-quality gDNA, FFPE-derived DNA, low-input samples, cell-free DNA, and existing methylation datasets. Each project is reviewed by our scientific team to match the clock objective with the appropriate methylation platform and bioinformatics strategy.
Clock-tailored QC pipeline: coverage completeness at clock-relevant CpGs, missing-data risk assessment, batch-effect review, and model-ready beta-value matrix generation
Support for established clocks (Horvath, Hannum, GrimAge, DunedinPACE), custom model training (Elastic Net, Random Forest), and multi-omics integration
Which Methylation Platform Fits Your Clock Objective
Every clock project begins with the same practical question: what methylation data do I need, and how much coverage is sufficient for reliable age prediction? The answer depends on whether you are discovering new age-associated CpGs, applying an existing clock to your cohort, or validating a defined marker set. The table below maps each platform to the clock use case it serves best, along with the trade-offs that affect study design and budget planning.
Platform
Coverage Profile
Best Fit for Clock Research
Practical Considerations
Whole-Genome Bisulfite Sequencing (WGBS)
Genome-wide, single-base resolution covering all CpG, CHG, and CHH contexts
First-generation clock discovery, multi-tissue models, cross-species clock development, and projects where novel age-associated loci must be identified rather than assumed
Higher sequencing cost and DNA input (500 ng – 1 µg); provides the most comprehensive methylome baseline for models that do not presuppose which CpGs matter
CpG-dense regulatory regions — promoters, CpG islands, enhancers — enriched by restriction digestion (RRBS) or enzymatic conversion (EM-seq)
Regulatory-region-focused clock profiling, promoter-centric aging models, and projects needing a cost-efficient balance between breadth and per-sample sequencing depth
Lower coverage outside CpG islands; EM-seq offers gentler conversion chemistry than bisulfite, improving data from lower-quality DNA starting material
Targeted Bisulfite Sequencing Panels
Selected known clock CpGs or custom age-associated marker sets at ultra-high sequencing depth
Validation studies, large cohort screening, cfDNA-based clock research, and cost-effective deployment of custom marker panels when the clock CpGs are already established
Requires pre-existing marker list; highest cost efficiency for cohort-scale screening; ultra-deep coverage enables confident detection at sites with partial methylation
DNA Methylation Arrays (Infinium EPIC v2 / 935K)
935,000+ predefined CpG probes with standardized, well-annotated content optimized for human methylation analysis
Compatibility with established array-trained clocks (Horvath, Hannum, GrimAge, DunedinPACE), large clinical or epidemiological cohorts, cross-study meta-analyses, and longitudinal comparisons
Fixed probe content limits discovery of novel markers; highest standardization across batches and laboratories; extensive published clock models built on the Infinium platform
Native Long-Read Methylation Profiling (Nanopore)
Single-molecule methylation detection across long DNA fragments without bisulfite conversion, preserving native base modifications
Haplotype-resolved methylation analysis, repetitive-region clock discovery, combined genetic–epigenetic interrogation from a single assay, and projects where bisulfite-induced degradation compromises data quality
Higher per-base error rate relative to short-read bisulfite methods; best applied when long-range methylation context (haplotype phasing, transposon silencing, satellite repeat methylation) addresses a specific biological question
Clock Research Scenarios We Support
Epigenetic clock research spans a wide methodological landscape — from applying established human clocks in clinical cohorts to developing novel multi-species aging models. The right platform, QC strategy, and analysis pipeline vary with each scenario. Below we describe the configurations we support and the decisions we make at project start to match the workflow to the research question.
Biological age comparison across treatment and disease groups
Profile methylation levels across case–control, longitudinal, or intervention cohorts to compare biological age trajectories or epigenetic age acceleration (EAA).
Deliver include sample-level beta-value matrices formatted for statistical modeling, group-wise age acceleration summaries, and correlation plots.
Platform recommendation: methylation arrays for established human clock compatibility; targeted panels for focused marker sets.
Custom clock model development
Identify age-associated CpGs from genome-wide or reduced-representation methylation data and train a project-specific clock model tailored to your cohort's age range, tissue type, and species.
Support Elastic Net, Random Forest, and other regression strategies selected based on the number of samples, CpG features, and intended model interpretability.
Platform recommendation: WGBS (maximum discovery breadth) or RRBS/EM-seq (regulatory-region focus with controlled sequencing budget).
Clock validation and cohort screening with targeted markers
Once the clock CpG list is defined — whether from published literature, array-based training, or prior discovery — profile those specific loci at high depth across validation or screening cohorts.
Evaluate cross-sample consistency, per-CpG coverage, missingness rates, and batch structure before integrating clock predictions into the analysis.
Platform recommendation: targeted bisulfite sequencing panels or multiplex amplicon approaches.
Array-based clock analysis with established models
Process samples on the Illumina Infinium platform with probe-level QC, functional normalization, and beta-value matrix generation formatted for established clock calculators.
Compatible with Horvath multi-tissue clock, Hannum clock, GrimAge, DunedinPACE, PhenoAge, and other array-trained models.
Researchers working with FFPE-archived tissues, plasma-derived cfDNA, laser-capture microdissection material, or limited biopsy samples need a platform that tolerates low DNA input and partial fragmentation.
We assess DNA yield, fragment size distribution, library complexity, and per-CpG coverage risk before committing to a specific assay path, and adjust the analysis plan to account for increased missingness at clock-relevant loci if needed.
Platform recommendation: RRBS or targeted panels (low-input tolerant); EM-seq for FFPE samples (gentler enzymatic conversion).
Multi-omics aging research
Integrate DNA methylation clock outputs with transcriptome, whole-genome, proteome, metabolome, or health-phenotype data from the same cohort to build a systems-level picture of aging biology.
Our Epigenomics Data Analysis Service supports multi-modal integration, biomarker discovery across omics layers, and pathway-level interpretation of age-associated molecular changes.
Platform recommendation: all methylation platforms are compatible; the integration strategy is defined during the project design phase based on available data types.
Sample Input Requirements and QC Guidelines
Sample quality and input quantity are the most frequently underestimated variables in methylation clock projects. A model trained on 500 ng of high-integrity gDNA will not perform the same way on data from degraded or low-yield material. We evaluate each sample against platform-specific thresholds before library preparation and adjust the clock analysis plan when sample quality falls outside the optimal range.
Sample Type
Recommended Input Range
Critical QC Parameters
Platform Compatibility Notes
High-quality genomic DNA (fresh or flash-frozen tissue, blood, cultured cells)
WGBS: 500 ng – 1 µg; RRBS/EM-seq: 50–100 ng; targeted panels: 10–50 ng; methylation arrays: 250–500 ng
Concentration (fluorometric), A260/280 (1.8–2.0), A260/230 (≥1.8), high molecular weight integrity by gel or TapeStation
Suitable for all platforms; recommended as the primary sample type for discovery-phase and WGBS-based clock projects
FFPE-derived DNA
≥200 ng when available; feasibility depends on fragment size distribution and amplifiability
EM-seq (enzymatic conversion, gentler than bisulfite) or RRBS recommended; WGBS generally not suitable; analysis pipeline requires coverage-aware filtering and imputation review
Cell-free DNA (plasma, serum)
Typically 2–4 mL plasma equivalent; cfDNA input of 1–30 ng post-extraction
cfDNA fragment size distribution (peak at ~166 bp), library complexity, adapter-dimer contamination, end-repair efficiency
Targeted bisulfite panels or ultra-low-input RRBS workflows strongly preferred; whole-genome approaches require considerable optimization and may not achieve sufficient coverage at clock-relevant loci
Existing methylation datasets
FASTQ, IDAT, processed beta-value matrix, or per-CpG coverage tables
Metadata completeness, genome build version, array platform version (450K/EPIC/EPICv2), probe annotation compatibility, batch structure, sample-level age and phenotype data
Suitable for reanalysis with alternative clock models, cross-cohort harmonization, meta-analysis, or integration with newly generated data from the same cohort
End-to-End DNA Methylation Clock Workflow
From project design and sample QC through methylation calling, normalization, and biological age estimation
Primary analysis — Sequence QC, alignment, and data review
Read-level quality inspection: base quality scores, adapter content, sequence duplication, and methylation-specific bias (bisulfite conversion rate, strand specificity).
Adapter trimming and low-quality base removal with project-appropriate parameters that preserve methylation information.
Bisulfite-aware alignment to the selected reference genome (hg38, mm39, or custom non-human reference) using validated aligners. Array data undergoes probe-level QC including detection P-values, bead-count filtering, and control-probe review.
Methylation status determination at each CpG site (and non-CpG context where the clock model requires it).
Coverage-based CpG filtering: loci below minimum read depth are flagged, and the impact on clock-model completeness is assessed.
Beta-value matrix generation, genomic annotation (promoters, gene bodies, enhancers, CpG islands, shores, shelves), batch-effect assessment using principal component analysis, and normalization (quantile, BMIQ, or functional normalization depending on platform and cohort structure).
Tertiary clock analysis — Biological age estimation, model training, and interpretation support
We convert normalized methylation profiles into the input format required by the target clock model. For projects using established clocks, we apply published coefficients (Horvath, Hannum, GrimAge, DunedinPACE, PhenoAge, or others) and report predicted age, EAA, and model-specific metrics. For custom clock development, we support feature selection, Elastic Net or Random Forest model training, cross-validation, and independent cohort testing. Outputs include age prediction scatter plots, sample clustering by predicted age, EAA group comparisons, and a written interpretation summarizing the clock results in the context of the study design. Where the project combines methylation data with transcriptome, genome, or phenotype information, our analysis can extend into multi-omics integration.